W ramach kursów uczestnicy zdobywają przede wszystkim umiejętności praktyczne. Kursantki i kursanci dzielą się na grupy, wybierają problem do rozwiązania, a następnie realizują projekty, które trafiają do ich portfolio. Przedstawiamy Wam efekty pracy zespołu IT DEPENDS, który w ramach kursu Data Science zbudował model oparty na uczeniu maszynowym, który umożliwia identyfikację potencjalnie niebezpiecznych asteroid na podstawie kluczowych parametrów takich jak średnica, prędkość, odległość od Ziemi czy jasność absolutna.
Skład zespołu
Bartłomiej Brzostek (LinkledIn), Elżbieta Chruściel (LinkedIn), Katarzyna Donaj (LinkedIn), Tomasz Mazur (LinkedIn)
MENTOR ZESPOŁU:
Mateusz Maj (LinkedIn)
Bartek, Ela, Kasia i Tomasz ucząc się Machine Learningu wspólnie opracowali model, który później opisali, aby pokazać kolejnym entuzjastom Data Science, jak wciągająca może być ta dziedzina i jakie naukowe przygody wiążą się z udziałem w kursie. Zachęcamy do lektury i zapraszamy na pokład kolejnej edycji 🙂
W naszym Układzie Słonecznym odkryto ponad milion asteroid, z których blisko 30 tysięcy klasyfikowanych jest jako Near-Earth Objects (NEO), czyli obiekty, które zbliżają się do naszej planety na odległość nie większą niż 48 milionów kilometrów. Obiekty bliskie Ziemi (NEO) mają różne rozmiary – od małych „meteoroidów” o średnicy zaledwie kilku metrów, po znacznie większe ciała o średnicy kilku kilometrów. Kiedy NEO okresowo uderzają w Ziemię, mniejsze obiekty nieszkodliwie rozpadają się i spalają w atmosferze, podczas gdy większe mogą spowodować lokalne zniszczenia na powierzchni, a nawet globalną katastrofę. Dlatego tak istotne jest wykrywanie i śledzenie tych, które mogłyby zderzyć się z Ziemią i ocena skali zagrożenia dla naszej planety.
Cel projektu
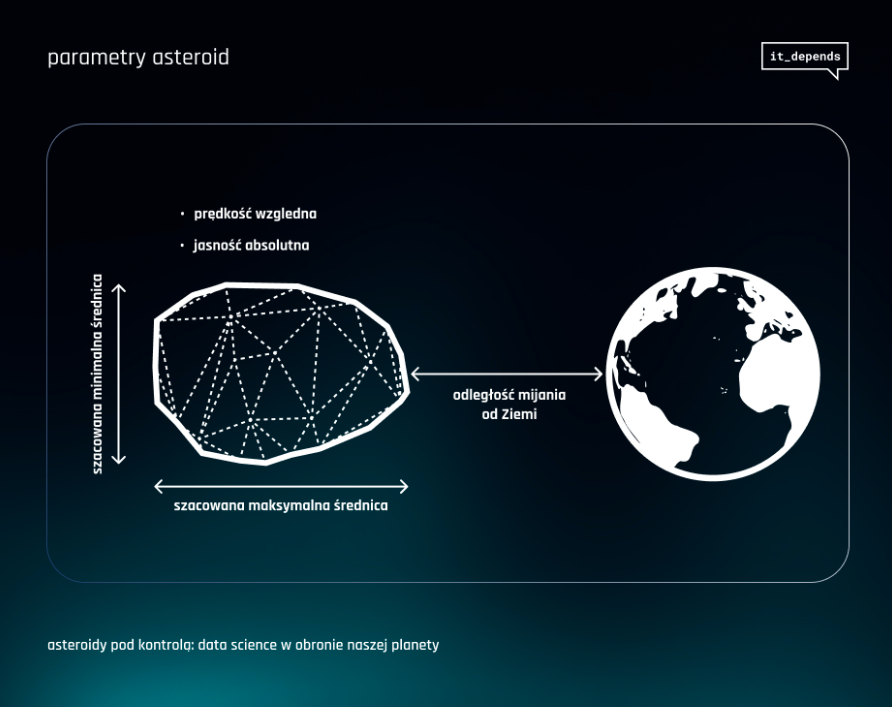
W naszym projekcie, inspirowanym Programem Obrony Planetarnej NASA, opracowaliśmy model oparty na uczeniu maszynowym, który umożliwia identyfikację potencjalnie niebezpiecznych asteroid na podstawie kluczowych parametrów takich jak średnica, prędkość, odległość od Ziemi czy jasność absolutna. Stworzyliśmy również aplikację bazującą na naszym modelu, która pozwala użytkownikom sprawdzić, czy dana asteroida może być niebezpieczna.
Projekt realizowaliśmy w ramach kursu Data Science w Infoshare Academy, gdzie mogliśmy wykorzystać w praktyce zdobytą na zajęciach wiedzę w zakresie analizy danych i modeli machine learning.
ETAPY REALIZACJI PROJEKTU:
Etap 1: Analiza danych
W naszym projekcie wykorzystaliśmy dane o asteroidach z kategorii NEO, pochodzące ze strony NASA (http://neo.jpl.nasa.gov/) i udostępnione na platformie Kaggle (https://www.kaggle.com/datasets/sameepvani/nasa-nearest-earth-objects).
Za pomocą języka Python oraz jego bibliotek Pandas i Matplotlib przeprowadziliśmy szczegółową analizę danych, co pozwoliło nam lepiej zrozumieć zależności między różnymi parametrami asteroid. Na przykład odkryliśmy silną korelację między średnicą a jasnością absolutną obiektów.
Etap 2: Dobór i optymalizacja modelu uczenia maszynowego
Ważnym etapem naszego projektu był wybór algorytmu skutecznie przewidującego, które asteroidy mogą stanowić zagrożenie dla Ziemi. Po przetestowaniu kilku metod, zdecydowaliśmy się na algorytm XGBoost. Jest to popularny model wykorzystujący technikę tzw. gradient boosting. XGBoost buduje serię drzew decyzyjnych, gdzie każde kolejne drzewo stara się poprawić błędy poprzednich.
Największym wyzwaniem okazała się duża dysproporcja klas w zbiorze danych – ponad 90% asteroid zostało sklasyfikowanych jako niezagrażające. Kiedy model jest trenowany na takim niezbalansowanym zbiorze, ma zbyt mało przykładów groźnych asteroid, aby skutecznie nauczyć się rozpoznawać ich charakterystyczne cechy. W efekcie model może błędnie klasyfikować kluczowe przypadki asteroid stanowiących zagrożenie jako niegroźne.
Przetestowaliśmy kilka podejść do rozwiązania problemu niezbalansowanych klas. Najpierw zastosowaliśmy różne techniki przetwarzania danych, mające na celu zrównoważenie proporcji między klasami w zbiorze, na którym model był trenowany. Wśród tych technik były algorytmy, które generują sztuczne przykłady dla klasy mniejszościowej (ang. oversampling) oraz takie, które redukują liczbę przykładów z klasy dominującej według określonego klucza (ang. undesampling). Na przykład, usuwane były próbki, które były najbardziej podobne do klasy mniejszościowej. Przetestowaliśmy również podejście łączące oversampling i undersampling, takie jak SMOTE-ENN (ang. Synthetic Minority Over-sampling – Edited Nearest Neighbors). SMOTE generuje nowe, syntetyczne próbki dla klasy mniejszościowej. Natomiast ENN usuwa asteroidy z klasy dominującej, jeśli większość asteroid o podobnych cechach należy do innej klasy. Dzięki tym działaniom poprawiła się wydajność modelu w identyfikowaniu rzadziej występujących klas.
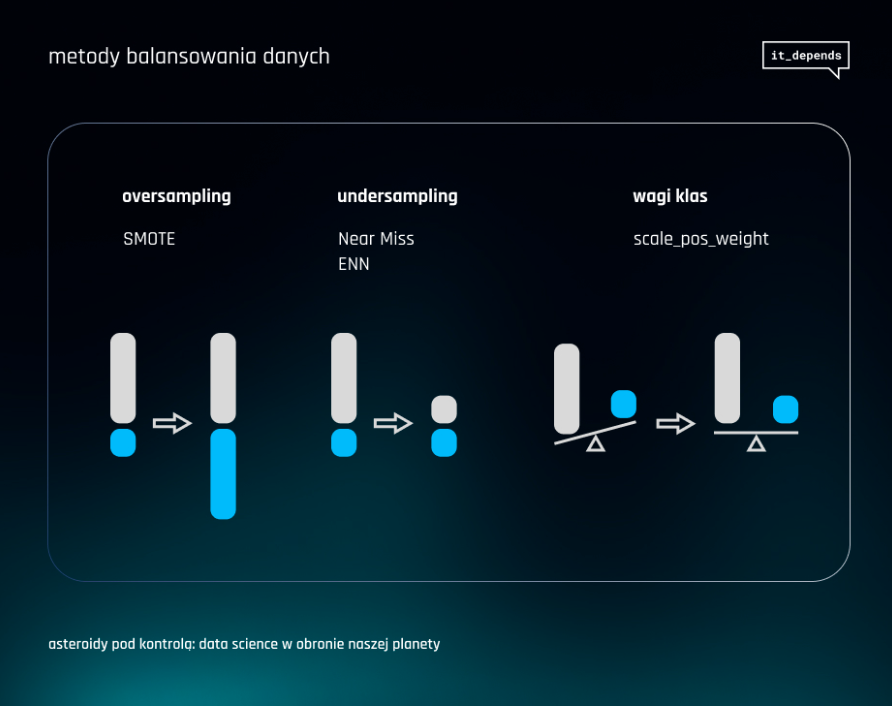
Bardziej skutecznym podejściem okazało się jednak wzmocnienie „ważności” rzadszych, niebezpiecznych asteroid poprzez zastosowanie parametru w modelu XGBoost, który definiuje, ile razy ważniejsza jest próbka klasy pozytywnej w stosunku do próbki klasy negatywnej podczas trenowania modelu. Domyślnie jego wartość wynosi 1, co oznacza, że obie klasy są traktowane równorzędnie. Zwiększenie wartości tego parametru sprawiło, że model przywiązywał większą wagę do asteroid, które mogą stanowić realne niebezpieczeństwo, mimo że występowały rzadziej w zbiorze danych. Dzięki temu model lepiej identyfikował te rzadkie asteroidy, co poprawiło jego zdolność do przewidywania potencjalnych zagrożeń.
Następnie zoptymalizowaliśmy model za pomocą dodatkowych parametrów, dążąc do tego, by nie przeoczył on żadnej niebezpiecznej asteroidy, nawet kosztem większej liczby fałszywych alarmów.
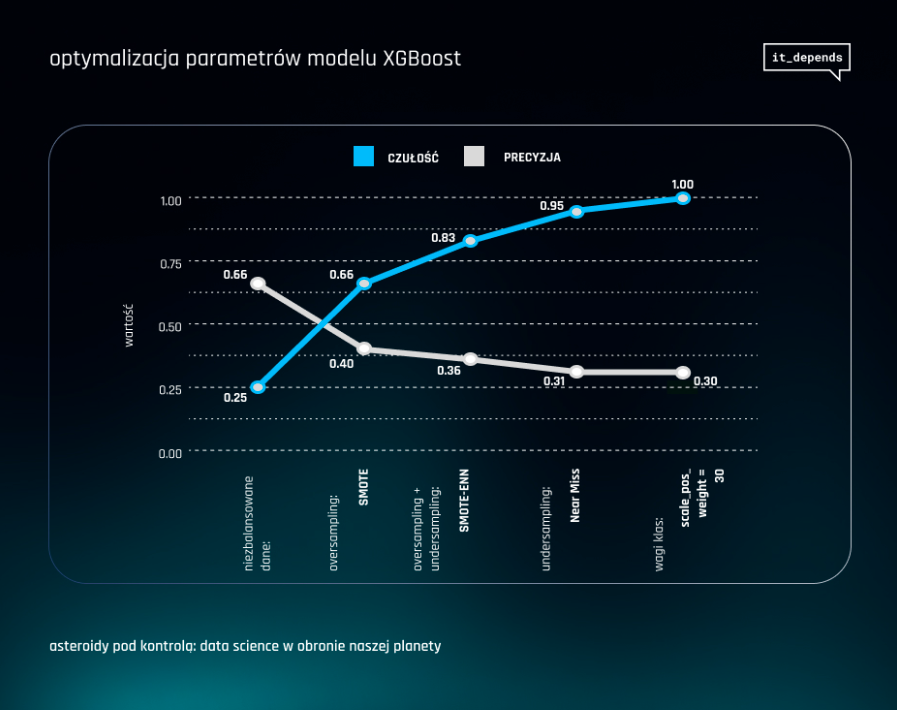
Etap 3: Ocena skuteczności modelu
Ostateczna wersja modelu uzyskała bardzo dobry wynik czułości w testach: na poziomie 100%, co oznacza, że nasz model wykrywał wszystkie potencjalnie niebezpieczne asteroidy. Precyzja modelu wyniosła natomiast 30%, co oznacza, że spośród asteroid uznanych przez model jako niebezpieczne, większość okazywała się fałszywymi alarmami. Niemniej jednak, uznaliśmy, że w kontekście planetarnej obrony, lepiej być nadmiernie ostrożnym, aby żadna zagrażająca asteroida nie została przeoczona.
Aby dodać naszemu projektowi osobistego akcentu, nazwaliśmy finalny model „Harry Stamper” – na cześć postaci z filmu „Armageddon”, która uratowała Ziemię przed asteroidą.
Etap 4: Budowa aplikacji – intuicyjne narzędzie do oceny zagrożenia
Nasz model postanowiliśmy udostępnić w formie aplikacji, która umożliwia łatwą ocenę, czy dana asteroida stanowi zagrożenie dla Ziemi. Stworzyliśmy prosty i intuicyjny interfejs użytkownika, który pozwala na wprowadzenie parametrów asteroidy, takich jak jej średnica czy odległość od Ziemi, za pomocą suwaków. Aplikacja analizuje wprowadzone dane i natychmiast klasyfikuje obiekt jako potencjalnie niebezpieczny lub niegroźny. Zadbaliśmy również o to, aby każda sklasyfikowana asteroida była automatycznie dodawana do bazy danych, co pozwala na dalsze monitorowanie i analizę nowych wyników. Projektując interfejs, inspirowaliśmy się futurystycznym stylem znanym z serialu „Westworld”, zapewniając nowoczesny wygląd i intuicyjną obsługę.
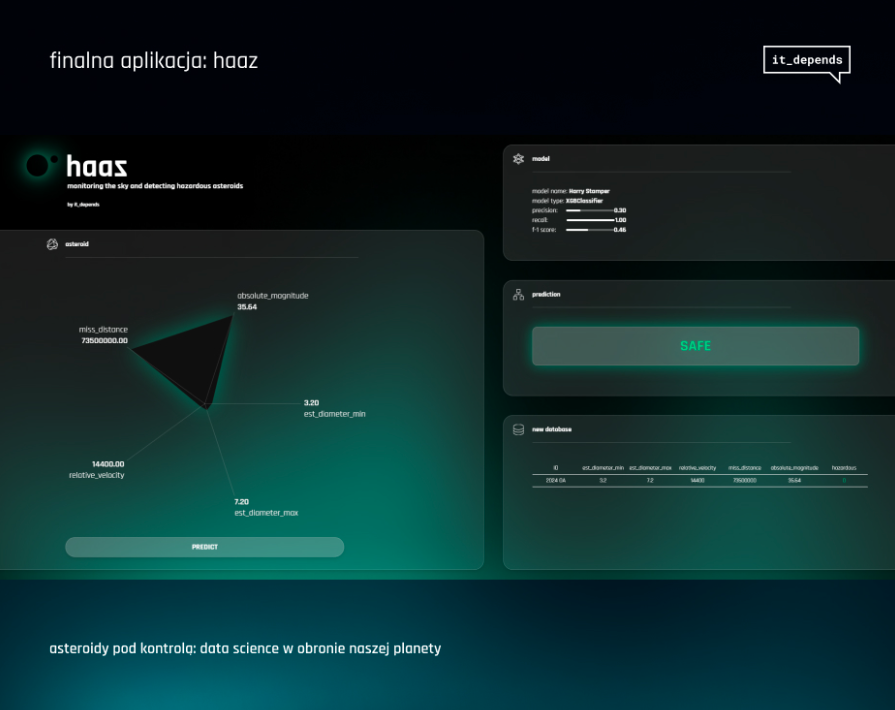
Repozytorium kodu aplikacji: https://shorturl.at/MgykN
PODSUMOWANIE I WNIOSKI – Data Science w praktyce
Nasz projekt był doskonałą okazją, by przekuć teoretyczną wiedzę z zakresu Data Science w praktyczne rozwiązania o realnym znaczeniu. Od wstępnej analizy danych po stworzenie modelu i budowę aplikacji – każdy etap nauczył nas cennych umiejętności, które z pewnością przydadzą się nam w przyszłości. Jednocześnie czujemy satysfakcję z rezultatu naszej pracy – aplikacji, która analizuje parametry asteroid i ocenia ich potencjalne ryzyko oraz umożliwia ich dalsze monitorowanie. Kluczowym elementem sukcesu była efektywna praca zespołowa, która umożliwiła nam wspólne pokonywanie wyzwań i czerpanie z różnorodnych umiejętności każdego członka zespołu. To doświadczenie było nie tylko praktyczne, ale także inspirujące, ukazując, jak potężnym narzędziem jest nauka o danych, gdy zastosujemy ją w realnych wyzwaniach. A dzięki współpracy mogliśmy wykorzystać pełen potencjał naszych umiejętności i stworzyć coś wyjątkowego.
Sprawdź kurs weekendowy Data Science + AI
Dane stały się prawdziwą walutą w dzisiejszych czasach. Firmy odkryły możliwości, jakie płyną ze zbierania danych. Mocniejsze i tańsze komputery sprawiają, że Data Science jest dostępna dla coraz mniejszych firm, co przekłada się na wzrost zapotrzebowania na specjalistów od danych. Jeśli chcesz nauczyć się wykorzystywać dane i tworzyć takie aplikacje jak powyżej, to zapisz się na kurs Data Science.