Termin9.05.2026 – 18.10.2026sprawdź liczbę godzin »
Kiedysobota, niedziela: 11:30 – 14:30
Cena (brutto)
6 500 zł
8 900 zł
Najniższa cena z 30 dni: 7 900 zł
Raty PayU 0%
Formy finansowania sprawdź »
Kurs weekendowy

 Zdalnie z trenerem na żywo
Zdalnie z trenerem na żywo
 Certyfikat
Certyfikat
![]() Dostęp do nagrań przez 6 mc-y
Dostęp do nagrań przez 6 mc-y

Jeśli Twoją pasją jest budowanie solidnych fundamentów pod systemy Big Data, a nie tylko analiza wyników, to szkolenie jest dla Ciebie. To ścieżka dla osób z zacięciem technicznym, które chcą wyjść poza ramy prostych baz danych i zająć się projektowaniem skalowalnych potoków (pipelines) oraz nowoczesnych ekosystemów danych.
Podstawowe wymagania:
– Znajomość podstawowej składni Pythona (wiedza zawarta w preworku kursu).
– Zdolność analizy danych i dobra znajomość matematyki.
– Angielski na poziomie min. B2 (praca z oprogramowaniem i dokumentacją).
Dla kogo jest kurs Data Engineer?
 Programiści Python gotowi tworzyć potoki danych i poznać narzędzie Apache Airflow
Programiści Python gotowi tworzyć potoki danych i poznać narzędzie Apache Airflow Administratorzy baz danych planujący przetwarzać w chmurze duże zbiory danych na żywo
Administratorzy baz danych planujący przetwarzać w chmurze duże zbiory danych na żywo


Rozwiń wszystkie

Czego się nauczysz w tej sekcji?
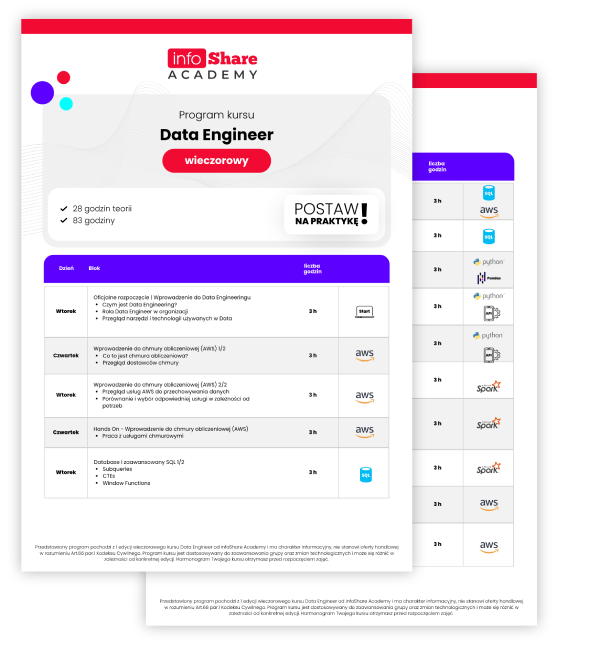
Git: poznasz podstawy pracy z systemem kontroli wersji Git, nauczysz się, jak śledzić zmiany w projekcie, a także dowiesz się, jak korzystać z repozytoriów i współpracować z innymi programistami.
Python: nauczysz się podstaw składni języka Python, w tym zmiennych, pętli i funkcji.
SQL: wykonasz podstawowe operacje na bazach danych z użyciem SQL oraz zrozumiesz, jak projektować proste schematy bazy danych.
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?
Czego się nauczysz w tej sekcji?

AWS

AWS S3

SQL

Kubernetes

Docker

Python

Pandas

NumPy

Polars
API

Hadoop

Spark

DynamoDB

Kafka

Amazon Redshift

Apache Airflow

Databricks

Snowflake
Joanna Garwacka
Kurs był świetny, jestem bardzo zadowolona. Nawet opcja nauki zdalnej (której się obawiałam) finalnie okazała się bardzo wygodna. Zakres merytoryczny bardzo obszerny, zajęcia prowadzone ciekawie, trenerzy cały czas służyli pomocą. Kurs otworzył mi oczy i też bardzo zainteresował tematyką Data Science (oraz programowaniem w SQL i Pythonie).


Dagmara Bromirska
Uważam, że kurs był zdecydowanie wartościowy, acz intensywny. Bardzo mi odpowiadała możliwość sprawdzenia świeżo zdobytej wiedzy podczas dużej liczby zajęć praktycznych i projektów. Wzbogaciłam wachlarz swoich umiejętności technicznych i mam jeszcze więcej chęci do działania!
Kacper Jędrczak
Kurs spełnił oczekiwania w pełni, wartościowych aspektów było bardzo dużo: zaczynając od solidnych podstaw z sqla, przez pythona, bardzo fajnie opracowaną statystykę, a na machine learningu i dość rozbudowanym deep learningu kończąc. Dużym plusem było przygotowanie merytoryczne i postawa trenerów – naprawdę przyjemnie się z Wami pracowało. Generalnie polecam, niezależnie od tego czy nie masz wiedzy w tym temacie w ogóle, czy też masz już podstawy i potrzebujesz je uporządkować i rozwinąć.
Bartosz Stasiak
Kurs spełnił moje oczekiwania. Pozwolił rozwinąć zainteresowania i potwierdził, że warto zdobyć nieco umiejętności IT, bo ich potencjał jest ogromny. Dodatkowo kurs odnowił we mnie głód wiedzy i poznawania czegoś nowego 🙂 Jako dużą zaletę kursu w InfoShare traktuję fakt, że zajęcia prowadzili różni trenerzy. Uważam, że takie podejście pozwala docenić różnorodność metod nauczania, a także lepiej ocenić – i docenić – jakość poszczególnych trenerów. Osobiście, cieszę się, że zajęcia prowadzili profesjonaliści, którzy znają realia pracy z poznawanymi narzędziami i wiedzą jakie są realne wyzwania i problemy pojawiające się w pracy na stanowisku, do którego kurs przygotowuje. Polecam.

Agnieszka Frąckiewicz
Customer Success Coordinator
agnieszka.frackiewicz@infoshareacademy.comAby zapisać się na kurs możesz wypełnić formularz, wysłać maila bezpośrednio do opiekunki lub zadzwonić. W przypadku zgłoszenia się przez formularz otrzymasz od razu maila ze szczegółowym programem kursu oraz informacjami o kolejnych krokach.
Zajęcia na kursie odbywają się w soboty i niedziele od 11:30 do 14:30.
Obowiązkowym punktem rozpoczęcia kursu jest przerobienie preworku – są to materiały do samodzielnej nauki. Otrzymasz od nas wszystkie niezbędne materiały, linki oraz instrukcje, jak krok po kroku zainstalować programy i narzędzia, z których będziesz korzystać w trakcie kursu. Przykładając się do jego wykonania, zapewniasz sobie i reszcie grupy sprawny start w kursie i możliwość bezproblemowego rozpoczęcia nauki i pracy nad projektem. Z drugiej strony, w przypadku naszych kursów – bardzo intensywnych i napakowanych wiedzą, zlekceważenie preworku może skutkować późniejszym nawarstwieniem się zaległości, które będzie niezwykle trudno nadrobić w trakcie kursu.
Kurs jest dla Ciebie, jeśli lubisz analizować dane, masz zamiłowanie do matematyki, lubisz rozwiązywać skomplikowane problemy lub jesteś osobą z technicznym zacięciem. Dodatkowo niezbędne do rozpoczęcia nauki na kursie Data Engineer są: znajomość języka angielskiego na poziomie min. B1/B2, wykonanie preworku, który otrzymasz po zapisaniu się na kurs, wysoka motywacja, dyspozycyjność – czas na zajęcia, ale również naukę w domu.
Główną przewagą kursu nad studiami jest warsztatowa forma zajęć – wiedzę zdobytą na zajęciach teoretycznych kursanci wykorzystują od razu na zajęciach praktycznych. Zarówno zajęcia teoretyczne, jak i warsztaty prowadzą doświadczeni trenerzy – praktycy. W Akademii dbamy o to, aby program kursu był dopasowany do aktualnej sytuacji na rynku pracy. Kursy są krótsze niż studia, co z jednej strony wiąże się większym natężeniem zajęć i dostarczanej wiedzy, a z drugiej sprawia, że szybciej możesz rozpocząć swój rozwój w obszarze Data Science. Na koniec – na kursach panuje bardzo dobra atmosfera, kursanci wspierają się wzajemnie i są w stałym kontakcie ze sobą i z trenerami na komunikatorze wewnętrznym w czasie trwania zajęć.
Jeśli chodzi o samo uczestnictwo w kursach, to wiek nie jest ograniczeniem. Nasze kursy kończyli zarówno 18-latkowie, jak i osoby 50+. Należy jednak pamiętać, że karierę w branży IT zaczyna się od stażu albo od stanowiska juniora, co może wiązać się z otrzymywaniem niższego wynagrodzenia niż na obecnym miejscu pracy, jeśli ma się już kilkanaście lat doświadczenia. Warto wziąć to pod uwagę zanim podejmie się decyzję o przebranżowieniu.
Na rynku jest dostępnych wiele form finansowania kursów, szczegółowe informacje znajdziesz na naszej stronie Finansowanie.
Tak, zajęcia są nagrywane i można z nich korzystać, żeby utrwalać wiedzę z zajęć.
Oczywiście, po zaliczeniu kursu otrzymasz od nas doceniany na rynku certyfikat infoShare Academy z informacją o zakresie kursu i terminie, w jakim kurs się odbywał. Certyfikat podpisany jest przez CEO infoShare Academy oraz Trenera prowadzącego kurs. Otrzymasz go w formacie PDF, dzięki czemu łatwo podzielisz się informacją o zdobytych kwalifikacjach na LinkedIn z potencjalnymi, przyszłymi pracodawcami lub klientami.